协程的原理
协程的原理
为什么要有协程?
要用易于理解的同步方式的代码表达来表示异步的东西,并且其拥有异步的性能。
同步与异步的优缺点
异步:性能高,但是代码逻辑比较复杂。 同步:性能低,代码逻辑较人易于理解。
如何实现协程?
- 先举一个简单的例子,现在有如下代码:
1 2 3 4 5 6 7 8 9 10 11 12
//同步,符合人类直觉 func(){ send(); recv(); } //异步,有三个线程调用以下代码,逻辑较复杂。 callback(){ recv(); } func(){ send_http(fd,callback); }
现想用上述同步的编程方式来实现异步,如下:
1 2 3 4 5 6 7 8 9
func(){ async_send(fd, callback); async_recv(fd, buffer); } async_xxx(){ if(1 == poll(fd,0)) { switch(); } }
switch操作原语:如switch(1,2)从1跳转到2。有以下三种实现方式:
1.setjmp/longjmp。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <stdio.h>
#include <setjmp.h>
jmp_buf env; //
void func(int arg) {
printf("func: %d\n", arg);
longjmp(env, ++arg);
}
int main() {
int ret = setjmp(env); //
if (ret == 0) {
func(ret);
} else if (ret == 1) {
func(ret);
} else if (ret == 2) {
func(ret);
} else if (ret == 3) {
func(ret);
}
return 0;
}
//使用这个方法逻辑还是较为复杂
2.ucontext。
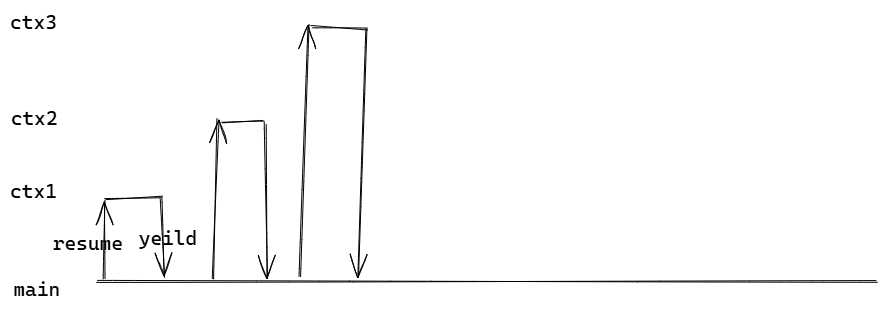
这里通过一张图来解释下面的使用ucontext来进行协程运作的代码,每个协程通过跳转到统一的调度器main_ctx中重新对其进行调度来实现并行运作。一个resume代表恢复到某个协程,yield代表让步本资源,回到调度器中等待重新调度,这两个原语过程看作一个switch。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include <ucontext.h>
#include <stdio.h>
// #include <asm-generic/ucontext.h>
ucontext_t ctx[2];
ucontext_t main_ctx;
int count = 0;
void func1(){
while(count++ < 20){
printf("func1: start\n");
swapcontext(&ctx[0], &ctx[1]);
printf("func1: end\n");
}
}
void func2(){
while(count++ < 20){
printf("func2: start\n");
swapcontext(&ctx[1], &ctx[0]);
printf("func2: end\n");
}
}
int main(){
char stack1[2048] = {0};
char stack2[2048] = {0};
getcontext(&ctx[0]);
ctx[0].uc_stack.ss_sp = stack1;
ctx[0].uc_stack.ss_size = sizeof(stack1);
ctx[0].uc_link = &main_ctx;
makecontext(&ctx[0], func1, 0);
getcontext(&ctx[1]);
ctx[1].uc_stack.ss_sp = stack2;
ctx[1].uc_stack.ss_size = sizeof(stack2);
ctx[1].uc_link = &main_ctx;
makecontext(&ctx[1], func2, 0);
printf ("start coroutine:\n");
swapcontext(&main_ctx, &ctx[0]);
printf("\n");
}
3. 汇编实现:
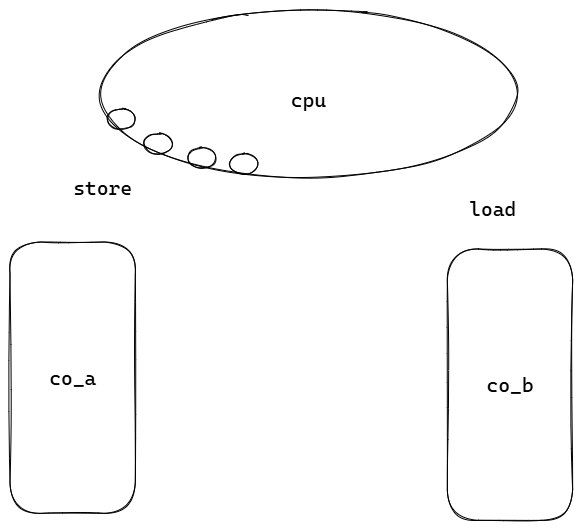
若从协程a转换到协程b: 将co_a中寄存器的值保存后,然后加载co_b。 如下代码所示:
store:
mov eax (co_a.a);
mov ebx (co_a.b);
load:
mov (co_b.a) eax;
mov (co_b.b) ebx;
三者之间的使用分析: 1.setjmp/longjmp:跨平台性最好,性能其次。 2.ucontext:实现最容易,性能最差。 3.汇编:对硬件体系结构需实现不同的版本,性能最高。
下一篇文章将会详细介绍如何将其应用到具体的业务场景中。
本文由作者按照 CC BY 4.0 进行授权